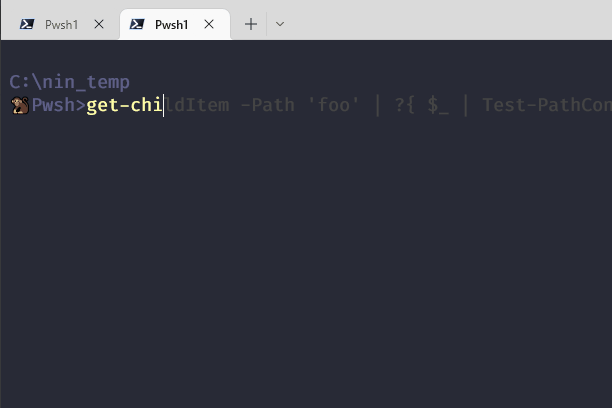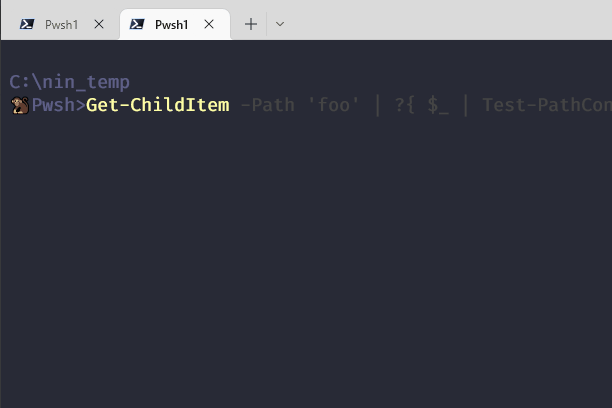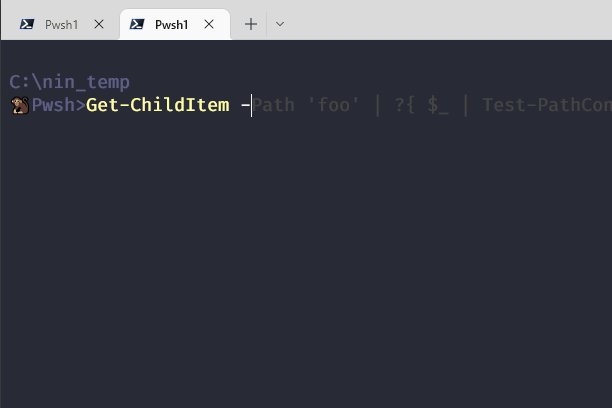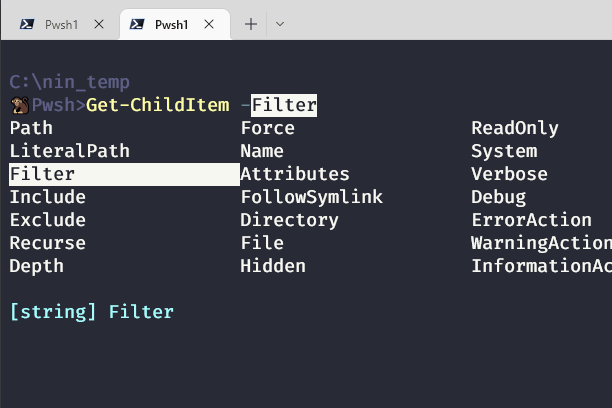
White Space before a function call is allowed
Whitespace between function calls and the name are allowed. Including newlines
These are equivalent statements:
= DoStuff( args )
// and
= DoStuff
(
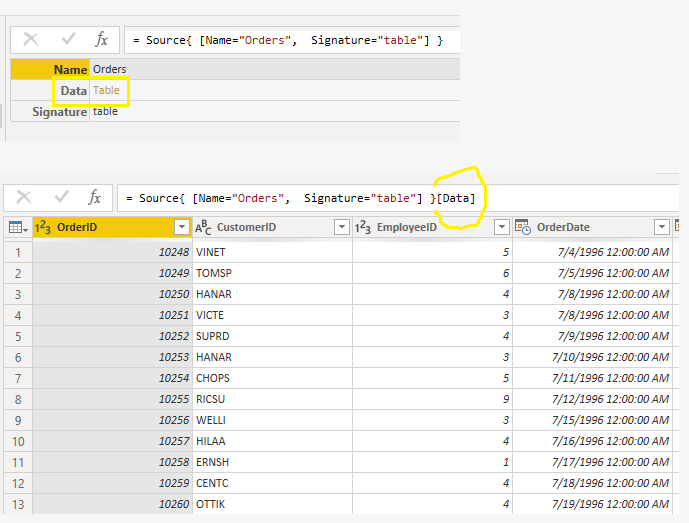
args )Record lookups also allow whitespace.
This is totally valid syntax wise. Not necessarily morally though.
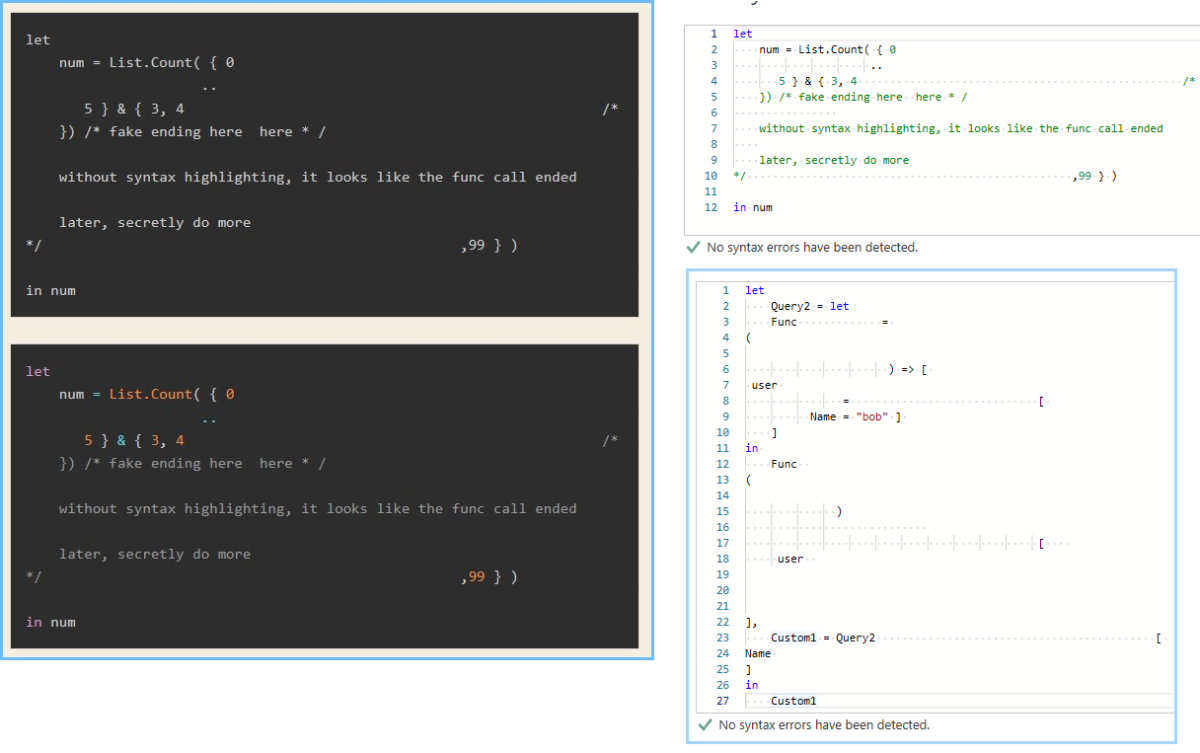
let
Func = () => [
user = [ Name = "bob" ]
]
in
Func
(
)
[
user
]Misleading Comments inside Lists, Records, and Function Calls are allowed
Comments do not affect parsing or execution.
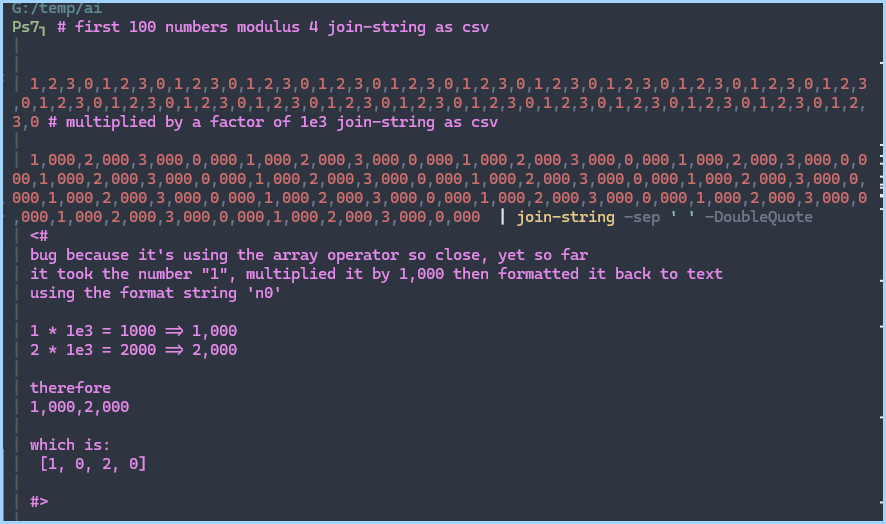
Without syntax highlighting it looks like 4 is the final item in the list
let
num = List.Count( { 0
..
5 } & { 3, 4 /*
}) /* fake ending here here * /
without syntax highlighting, it looks like the func call ended
later, secretly do more
*/ ,99 } )
in numNow it’s slightly easier
let
num = List.Count( { 0
..
5 } & { 3, 4 /*
}) /* fake ending here here * /
without syntax highlighting, it looks like the func call ended
later, secretly do more
*/ ,99 } )
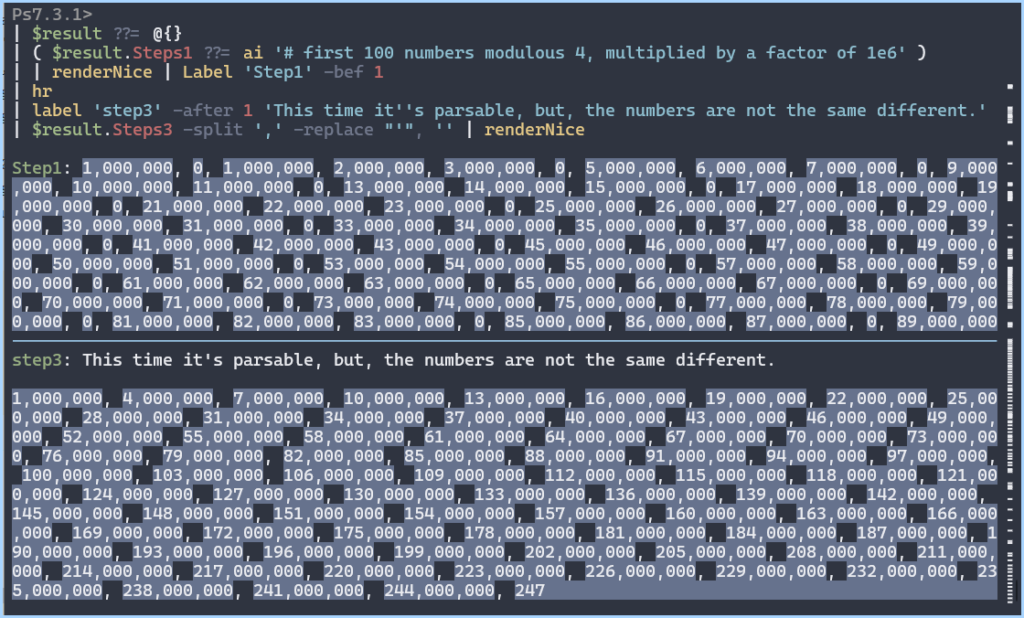
in numThe list operator .. allows a lot of expressions
You can use inline comments, resuming the list expression later
let
num = List.Count( { 0
..
5 } & { 3, 4 /*
now do more */ } )
in numYou don’t have to wrap the try-catch expressions in parenthesis.
let l = {
try "foo" + 99 catch (e) => 3 ..
try File.Contents( "invalid" ) catch () => 7 }
in
l = { 3..7 } // is trueThis version gave an interesting error. I thought perhaps try-catch expressions doesn’t work for inline list indices ?
let g = {
try 10 catch (e) => 3 ..
try 27 / 0 catch () => 53 }
in gExpression.Error: The number is out of range of a 32 bit integer value.
Details:
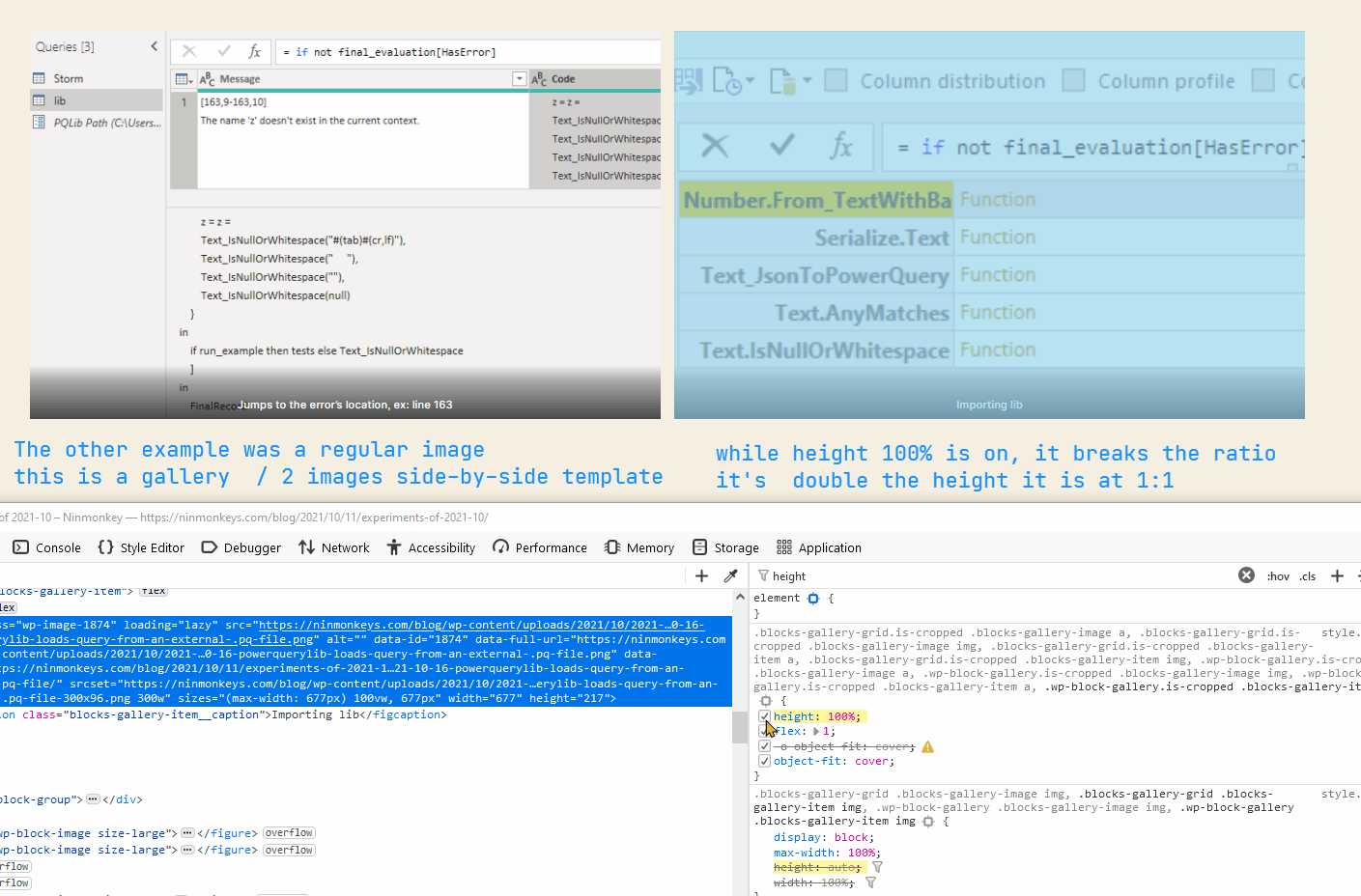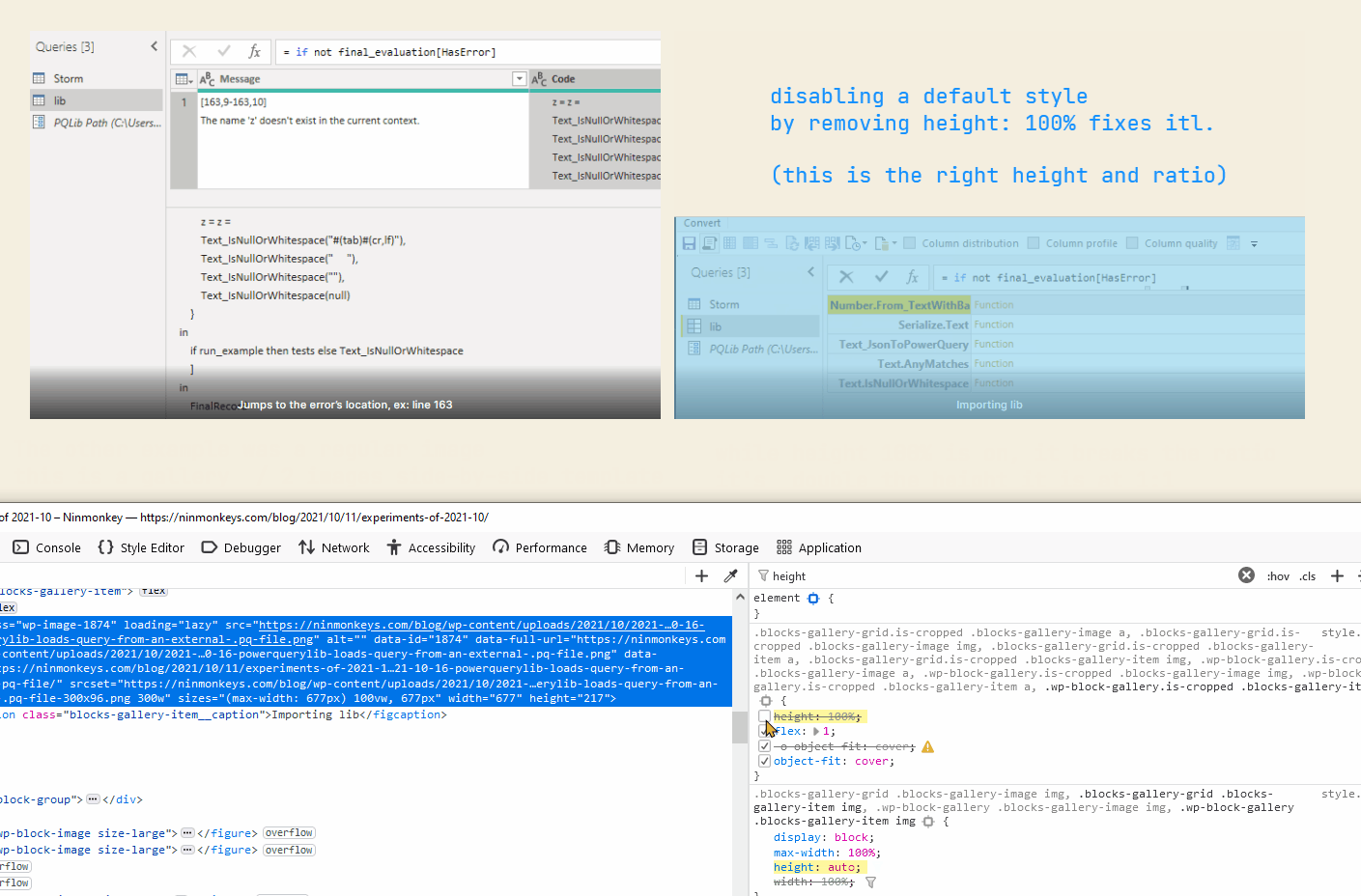
InfinityBut then realized division by 0 in power query does not throw an error record. It has the type number.
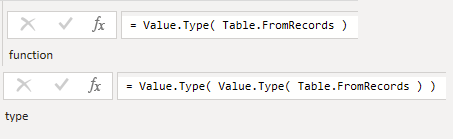
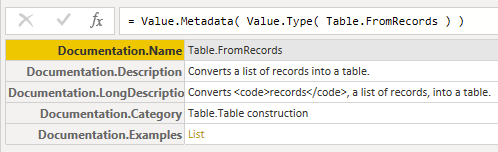
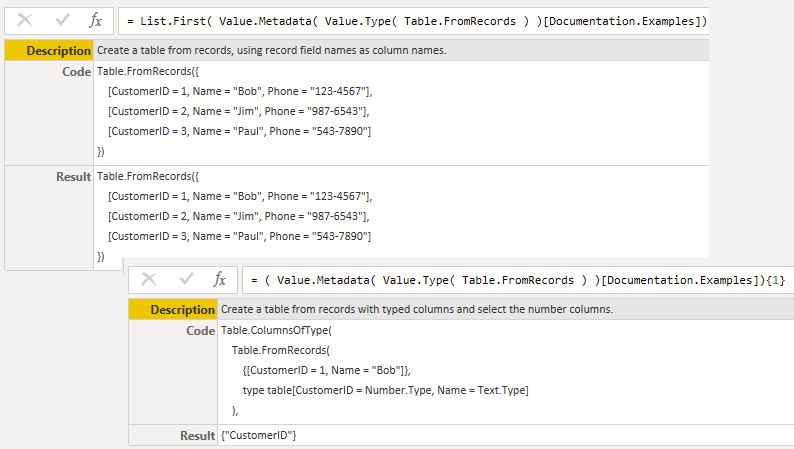
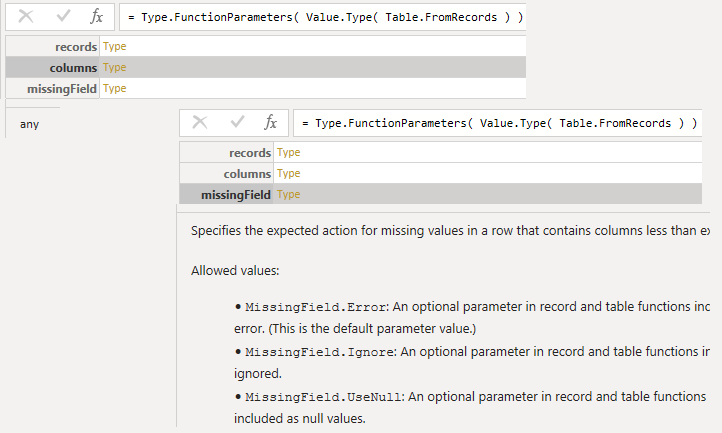
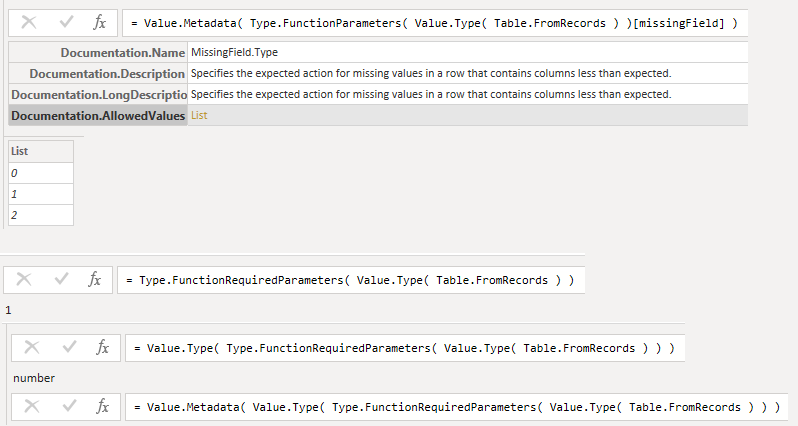
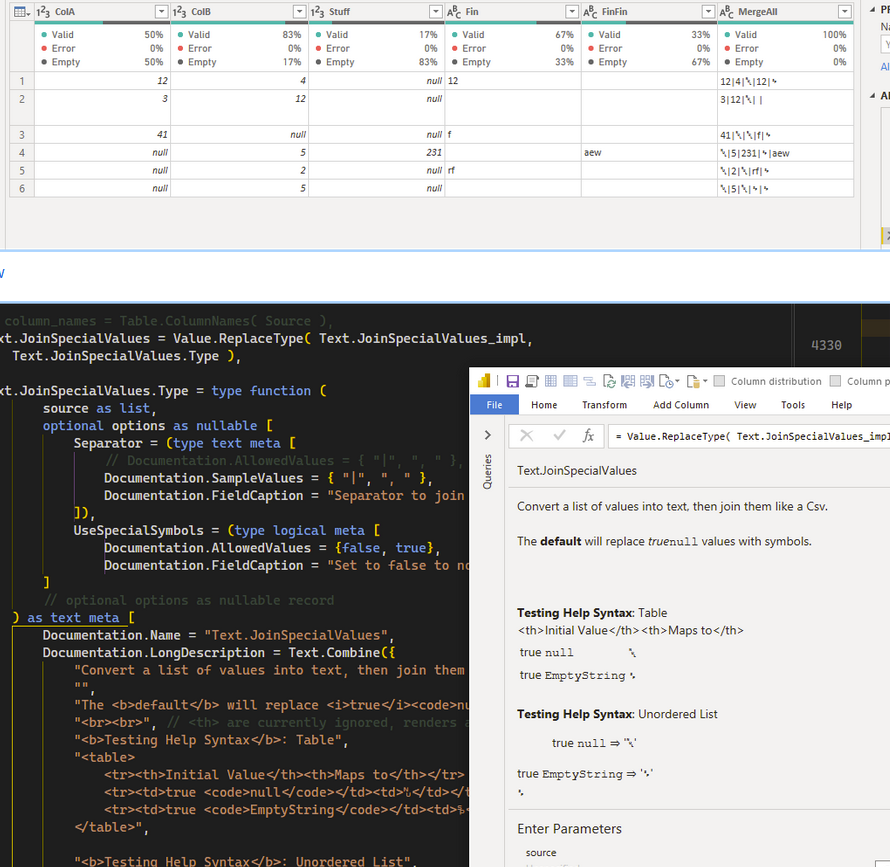


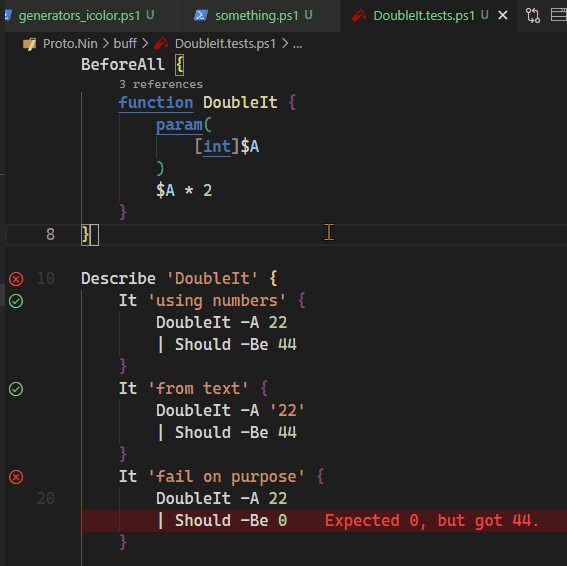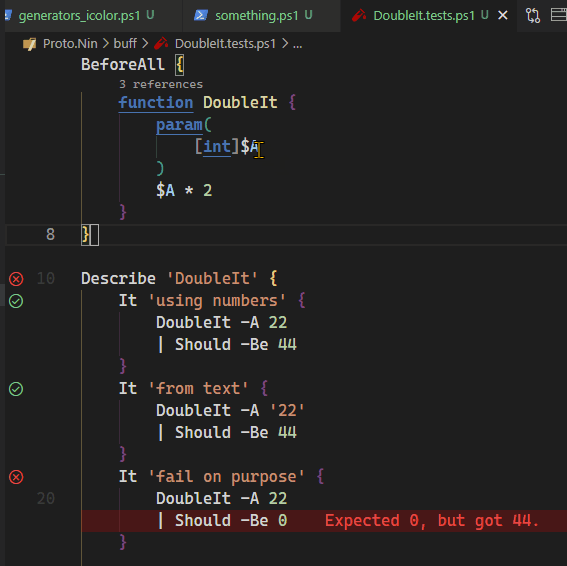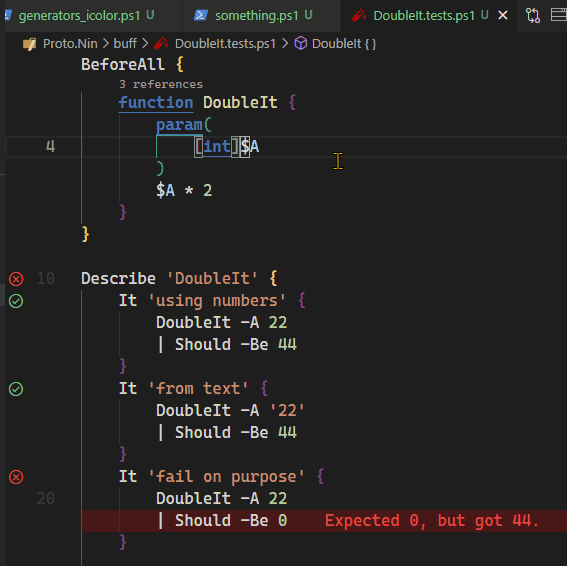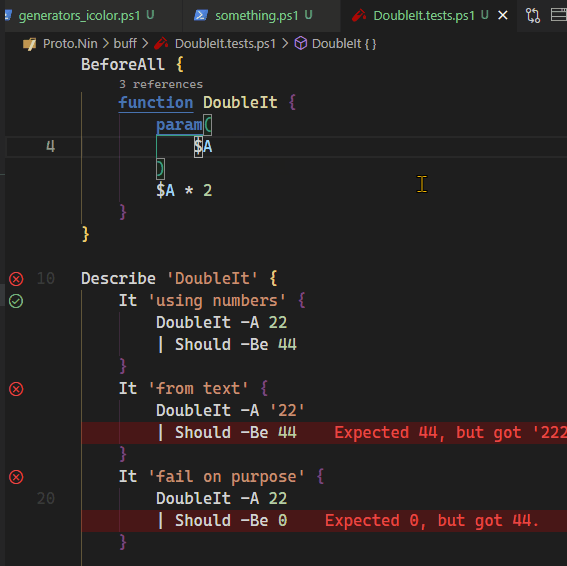
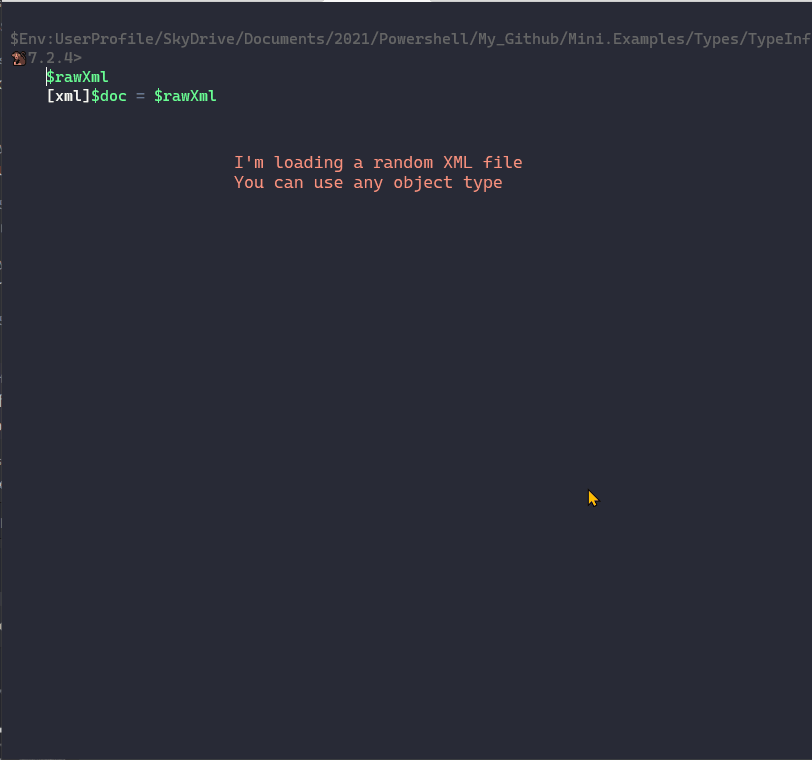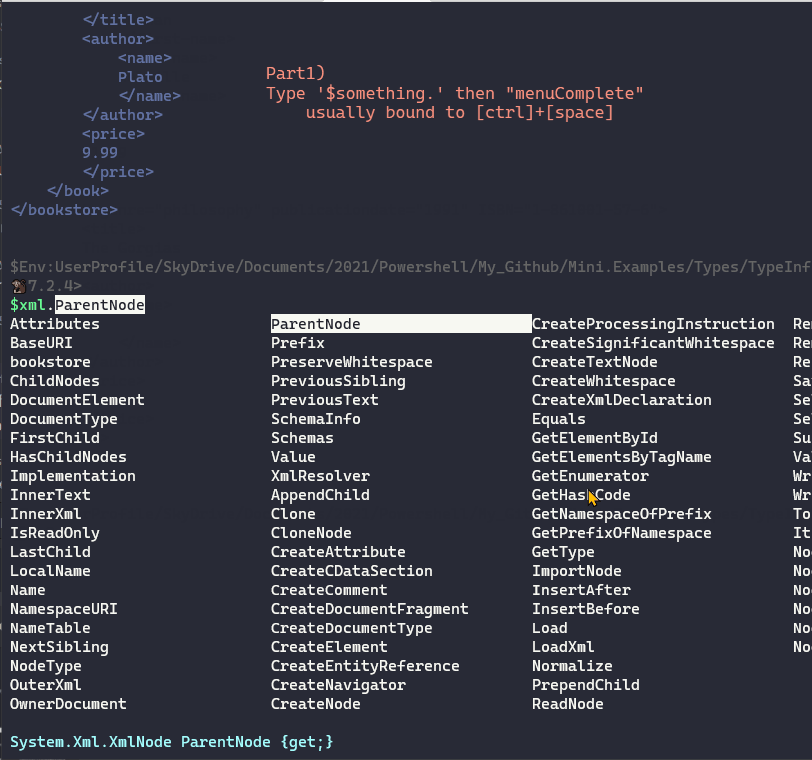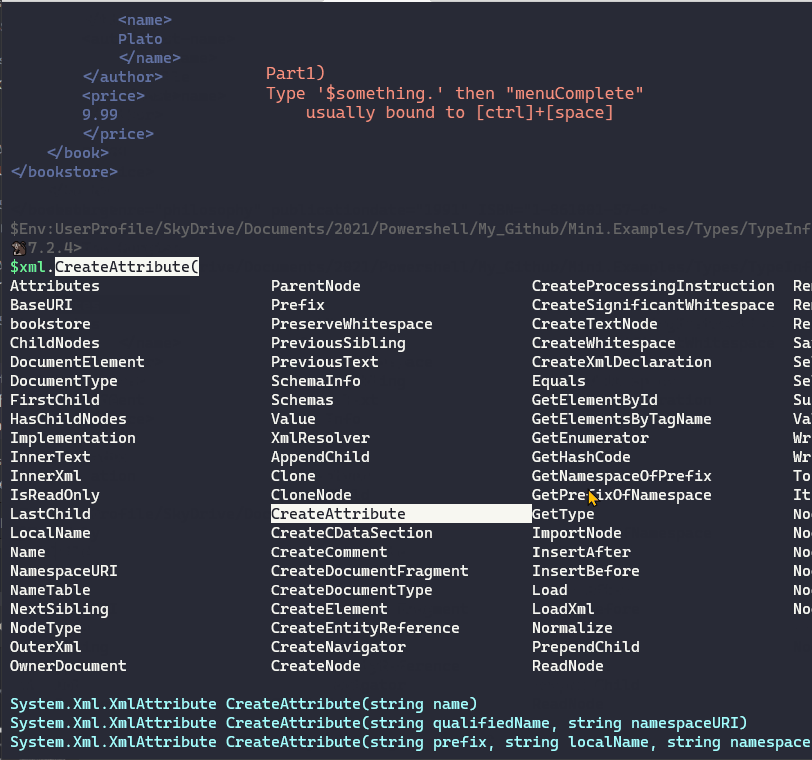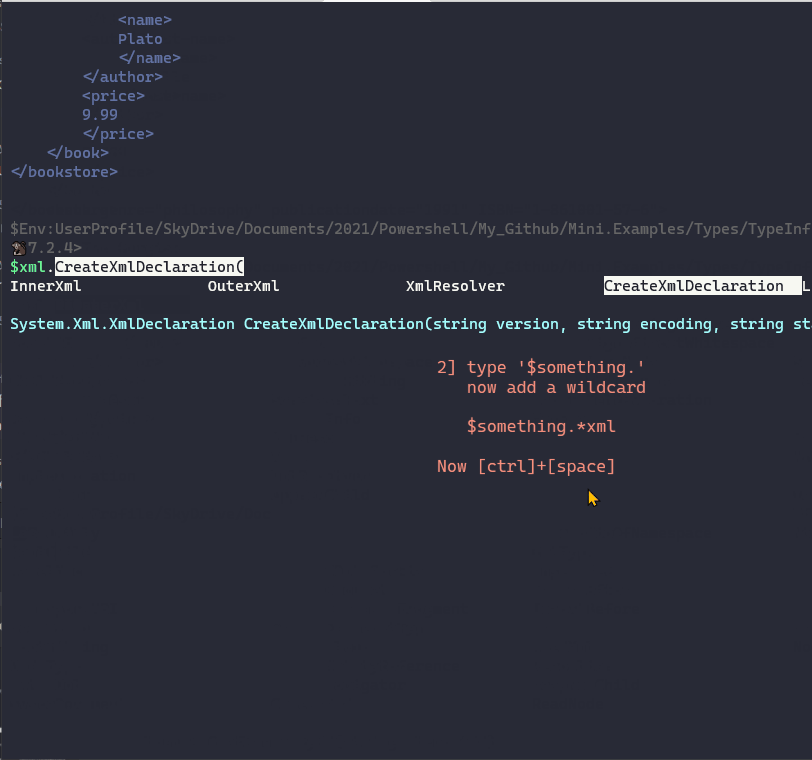

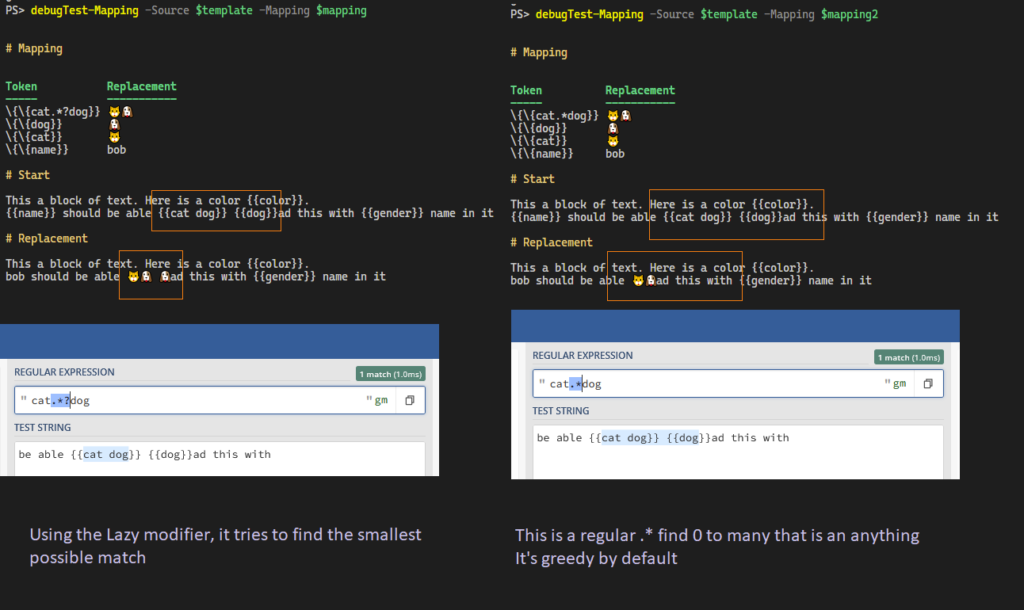
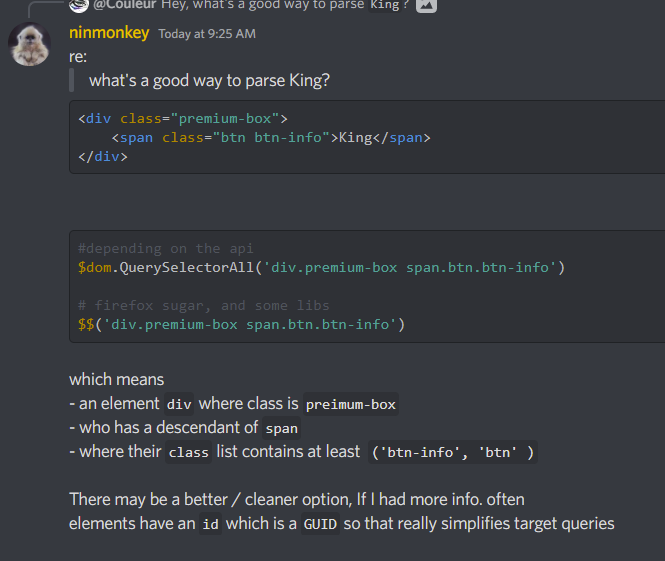

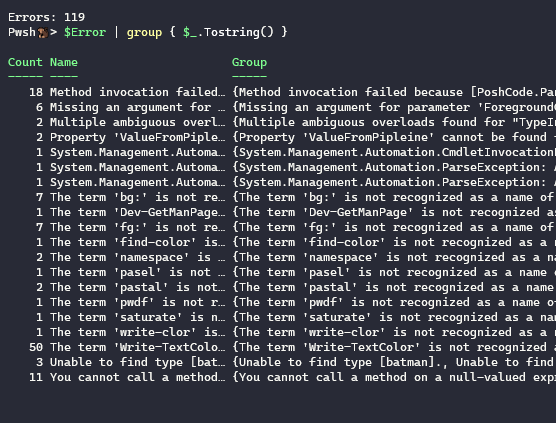
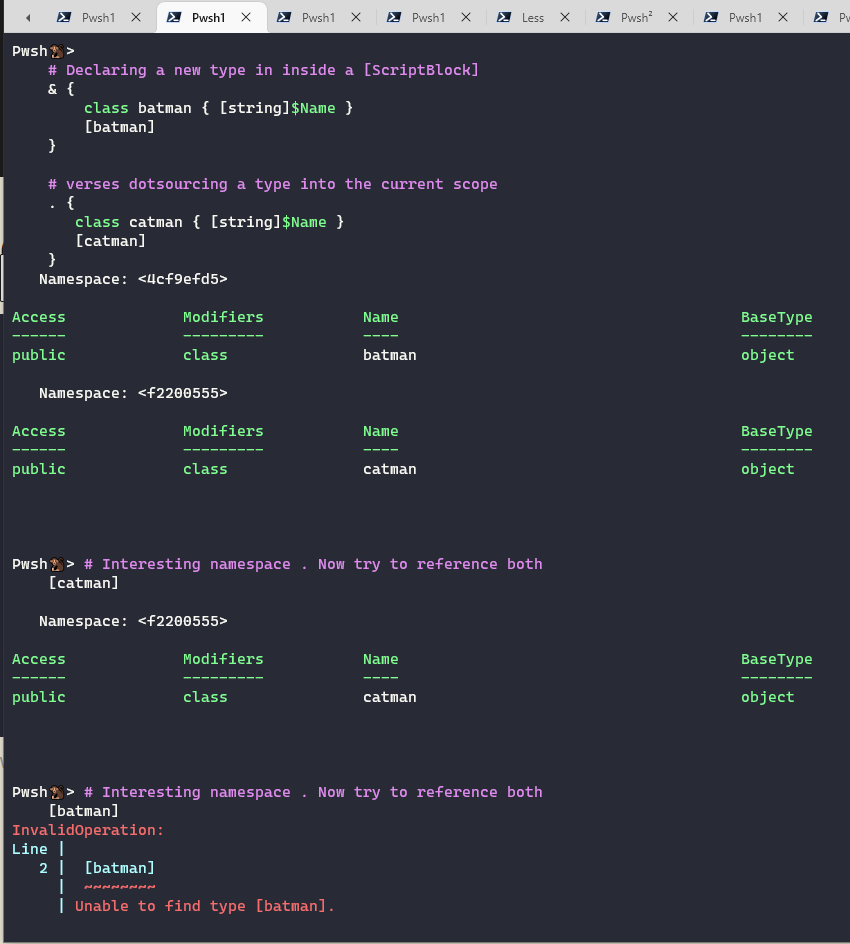
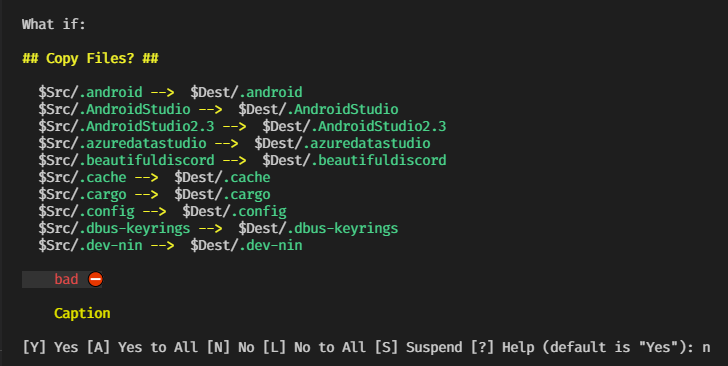
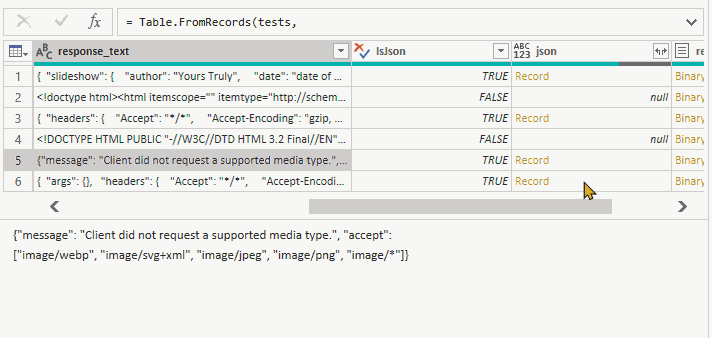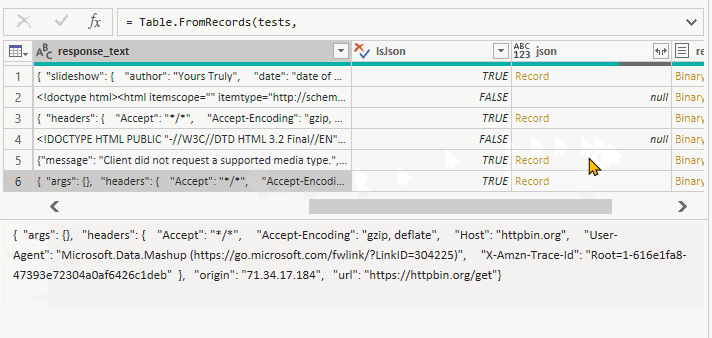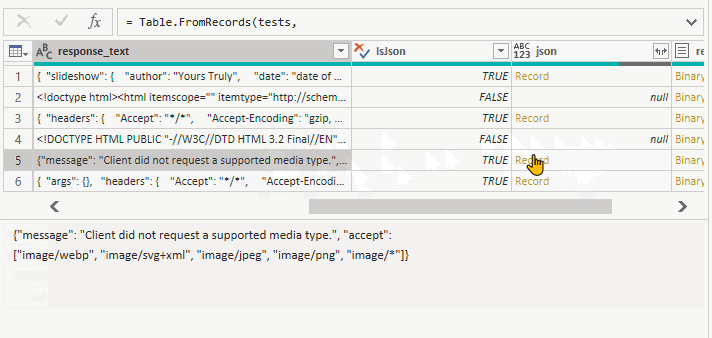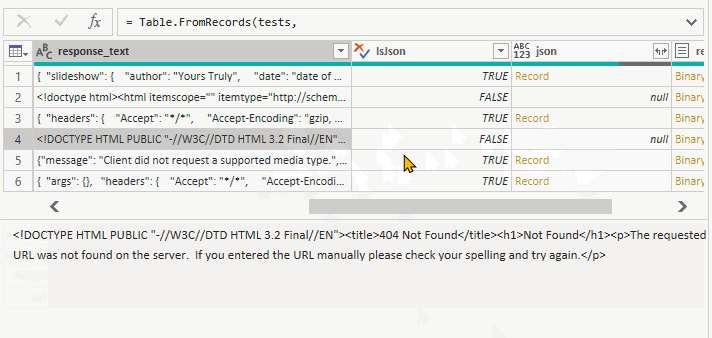

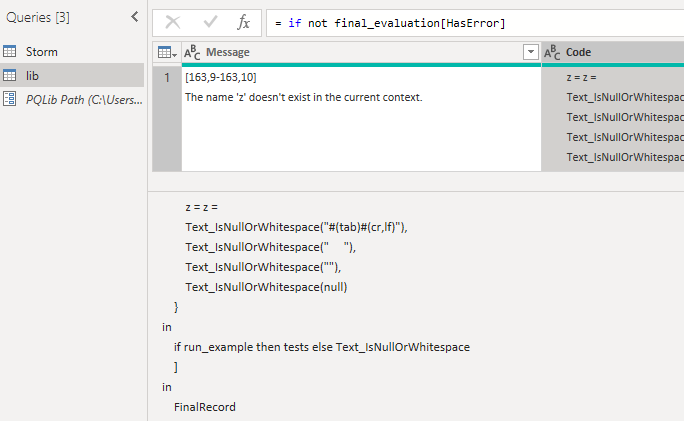
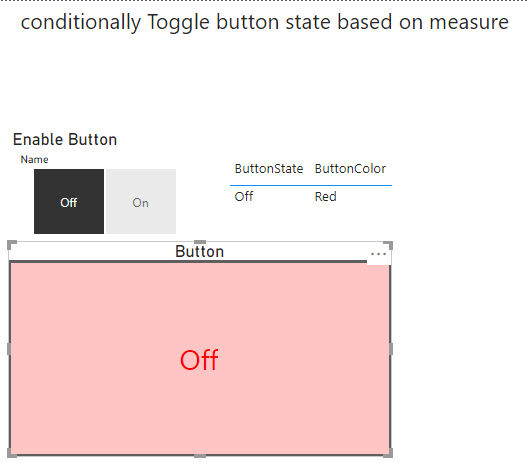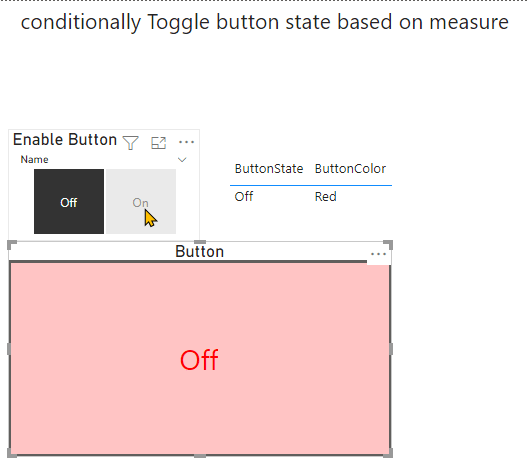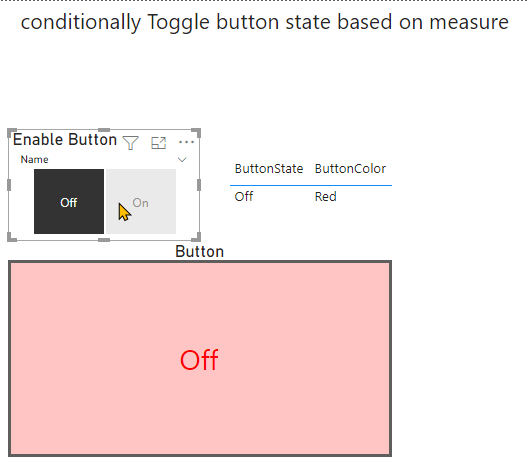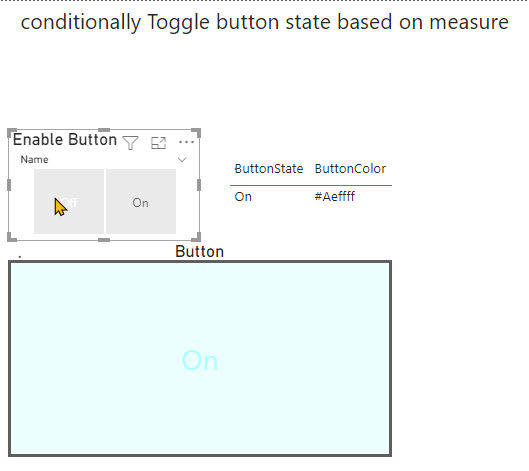
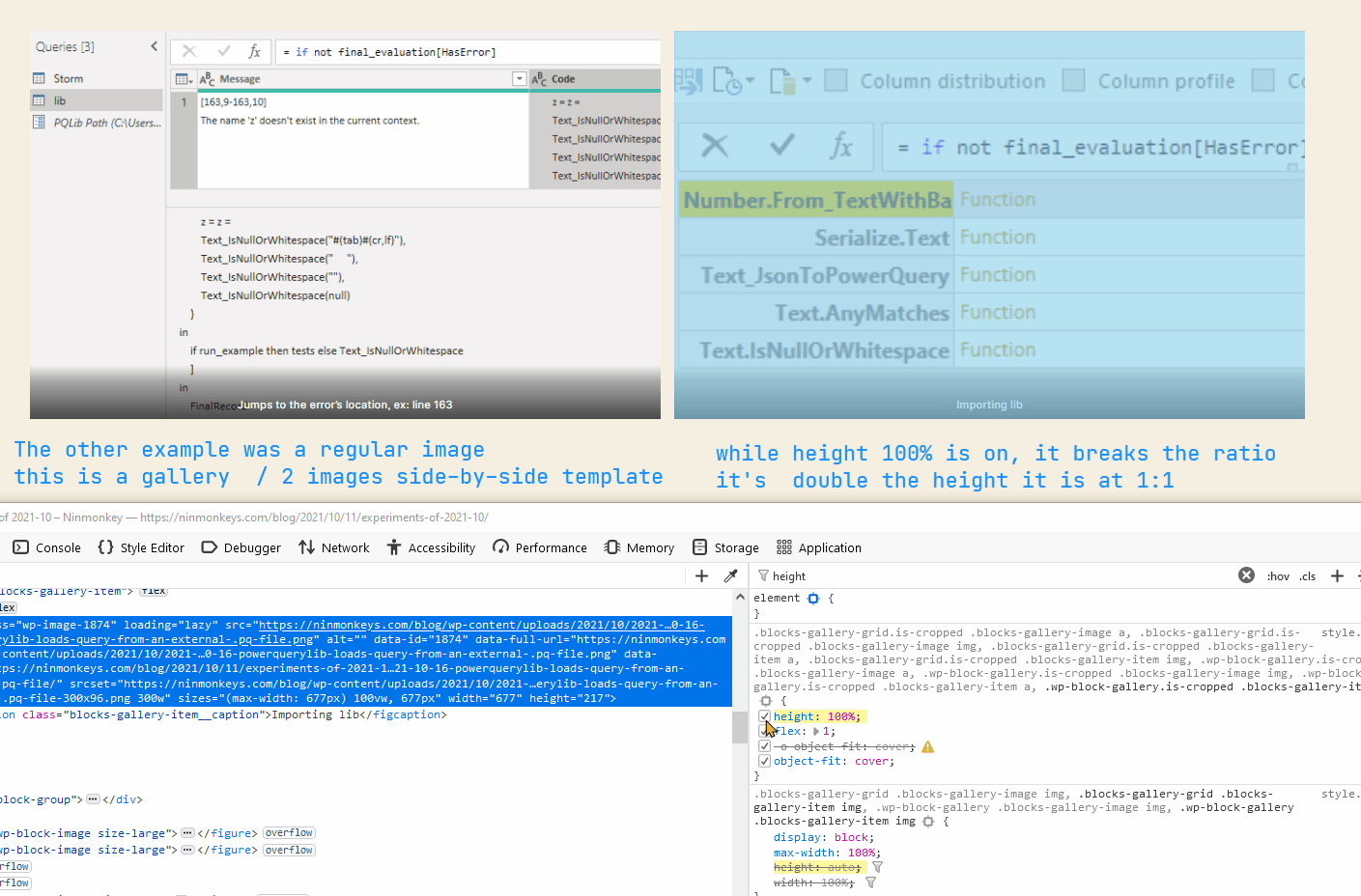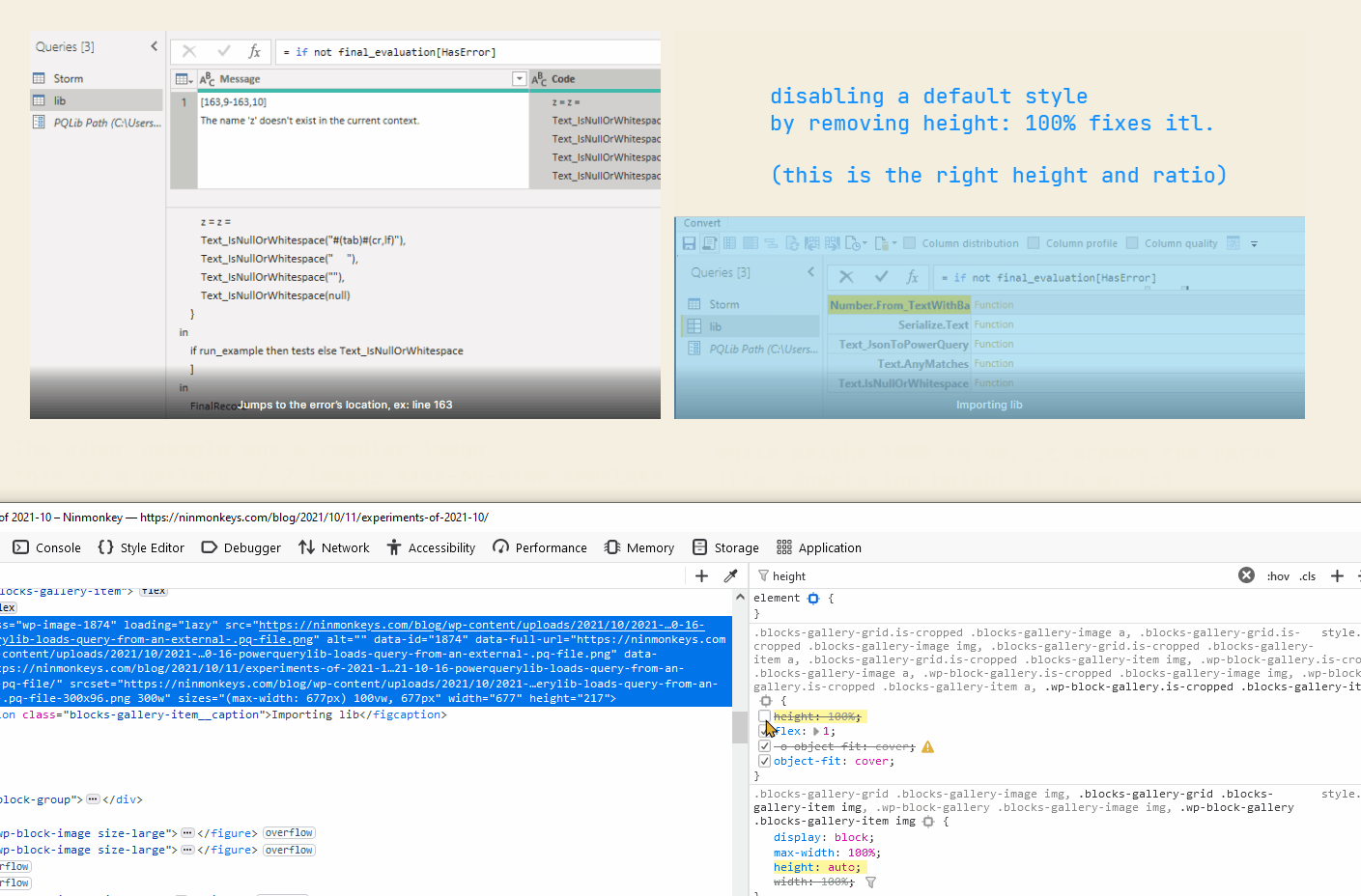
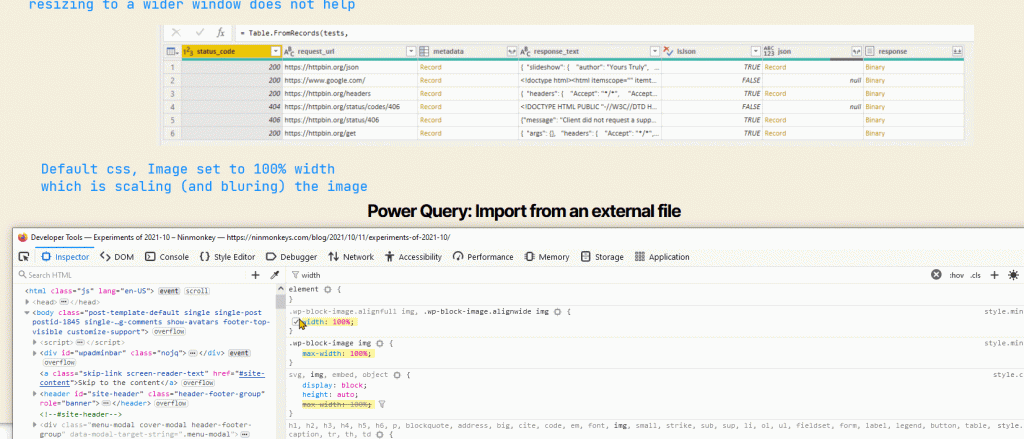
{kind=link}
{kind=link}
{kind=link}