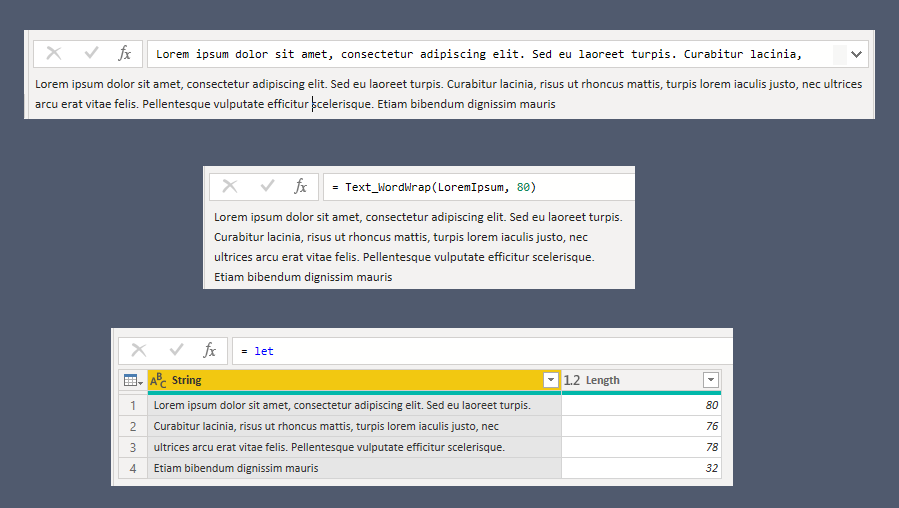
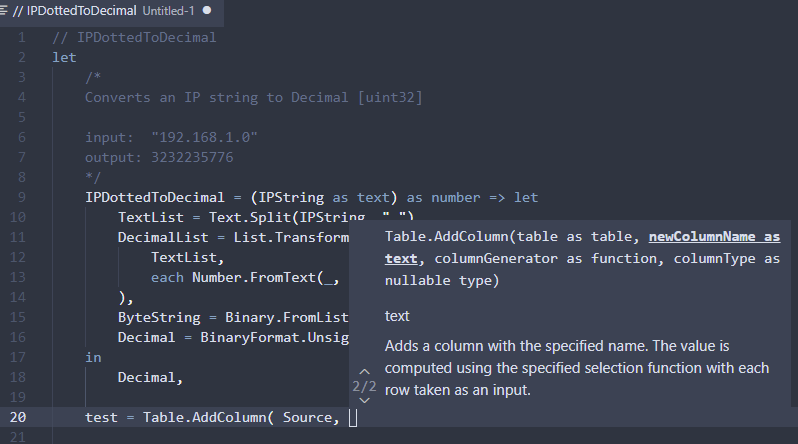
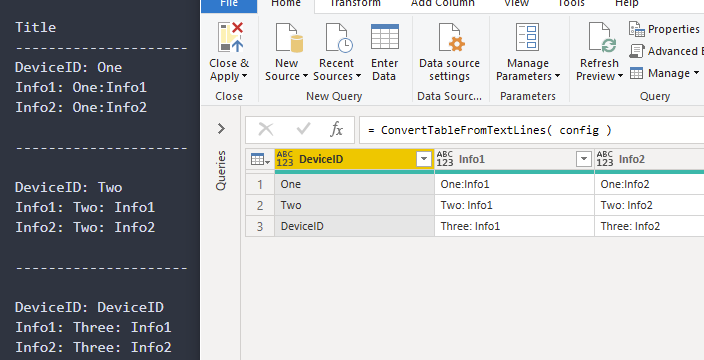
How to wrap long lines, *without* splitting words. The input is a very long string, with no newlines:
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Sed eu laoreet turpis. Curabitur lacinia, risus ut rhoncus mattis, turpis lorem iaculis justo, nec ultrices arcu erat vitae felis. Pellentesque vulputate efficitur scelerisque. Etiam bibendum dignissim mauris
Query
<a href="https://docs.microsoft.com/en-us/powerquery-m/list-accumulate">List.Accumulate</a> is an aggregate function. I’m using it to “sum” — to add strings together. If the current line plus the next word is longer than 80 characters, then insert a newline first.
To find the length of the current line, I only want the length after the very last newline. Occurrence.Last returns the last match, else -1 if nothing is found.
let
LoremIpsum = "Lorem ipsum dolor sit amet, consectetur adipiscing elit. Sed eu laoreet turpis. Curabitur lacinia, risus ut rhoncus mattis, turpis lorem iaculis justo, nec ultrices arcu erat vitae felis. Pellentesque vulputate efficitur scelerisque. Etiam bibendum dignissim mauris",
// calculate length of string *after* the rightmost newline
Text_LengthAfterNewline = (string as text) as number =>
let
posLastNewline = Text.PositionOf(string, "#(lf)", Occurrence.Last),
posOffset = if posLastNewline <> -1 then posLastNewline else 0,
deltaLen = Text.Length(string) - posOffset
in
deltaLen,
// word wraps text
Text_WordWrap = (string as text, max_width as number) as text =>
let
words = Text.Split(string, " "),
accum_result = List.Accumulate(
words, "",
(state as text, current as text) as text =>
let
len = Text_LengthAfterNewline(state) + Text.Length(current) + 1,
maybeNewline =
if len > max_width then "#(lf)" else "",
accum_string = Text.Combine({state & maybeNewline, current}, " ")
in
accum_string
)
in
accum_result,
wrapped_text = Text_WordWrap(LoremIpsum, 80)
in
wrapped_text
The final result is 80 characters wide or less
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Sed eu laoreet turpis.
Curabitur lacinia, risus ut rhoncus mattis, turpis lorem iaculis justo, nec
ultrices arcu erat vitae felis. Pellentesque vulputate efficitur scelerisque.
Etiam bibendum dignissim mauris
Validating lengths of each line
let
Source = #"wrap lines",
validate_lengths =
let
lines = Text.Split(Source, "#(lf)"),
lengths = List.Transform(
lines,
each [ String = _, Length = Text.Length(_) ])
in
Table.FromRecords(
lengths,
type table[String = text, Length = number],
MissingField.Error )
in
validate_lengths
Check out the new tutorial at https://blog.powp.co/my-power-query-web-contents-cheat-sheet-6a5bbfdce5eb
Web.Contents without Refresh Errors
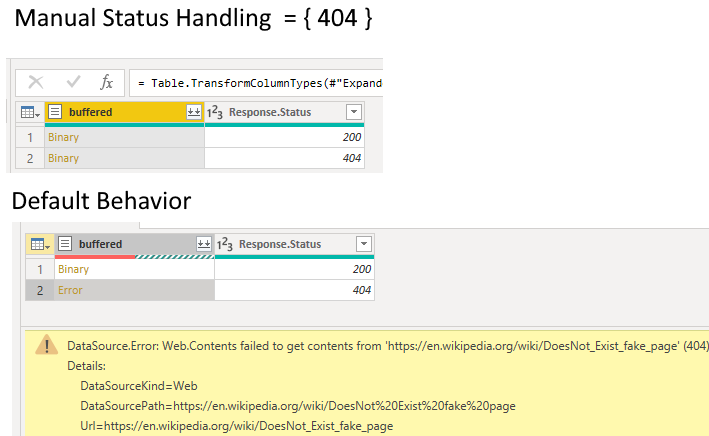
The main cause of Web.Contents not refreshing can be fixed by adding the options[Query] and options[RelativeaPath] parameters. (The UI doesn’t create them for you)
/* web request, act based on the HTTP Status Code returned
see more:
override default error handling: https://docs.microsoft.com/en-us/power-query/handlingstatuscodes
example wait-for loop: https://docs.microsoft.com/en-us/power-query/waitretry#manualstatushandling
*/
let
WikiRequest = (pageName as text) as any =>
let
BaseUrl = "https://en.wikipedia.org/wiki",
Options = [
RelativePath = pageName,
ManualStatusHandling = {400, 404}
],
// wrap 'Response' in 'Binary.Buffer' if you are using it multiple times
response = Web.Contents(BaseUrl, Options),
buffered = Binary.Buffer(response),
response_metadata = Value.Metadata(response),
status_code = response_metadata[Response.Status],
final_result = [
buffered = buffered,
response_metadata = response_metadata
]
in
final_result,
Queries = {"Cat", "DoesNot Exist fake page"},
Items = List.Transform(
Queries,
each WikiRequest( _ )
),
ResponseTable = Table.FromRecords(
Items,
type table[buffered = binary, response_metadata = record], MissingField.Error
),
#"Expanded HTTP Status Codes" = Table.ExpandRecordColumn(ResponseTable, "response_metadata", {"Response.Status"}, {"Response.Status"}),
#"Changed Type" = Table.TransformColumnTypes(#"Expanded HTTP Status Codes",{{"Response.Status", Int64.Type}})
in
#"Changed Type"
WebRequest: Wrapper with Better Defaults
You can get the full file with extra comments: WebRequest.pq
let
/*
Example using this url:
(https://www.metaweather.com/api/location/search?lattlong=36.96,-122.02)
WebRequest(
"https://www.metaweather.com",
"api/location/search",
[ lattlong = "36.96,-122.02" ]
)
Details on preventing "Refresh Errors", using 'Query' and 'RelativePath':
- Not using Query and Relative path cause refresh errors:
(https://blog.crossjoin.co.uk/2016/08/23/web-contents-m-functions-and-dataset-refresh-errors-in-power-bi/)
- You can opt-in to Skip-Test:
(https://blog.crossjoin.co.uk/2019/04/25/skip-test-connection-power-bi-refresh-failures/)
- Debugging and tracing the HTTP requests
(https://blog.crossjoin.co.uk/2019/11/17/troubleshooting-web-service-refresh-problems-in-power-bi-with-the-power-query-diagnostics-feature/)
*/
WebRequest = (
staticPath as text, // domain
relativePath as text, // basically use everything after ".com" to "?"
optional query as nullable record, // url query string
optional asRaw as nullable logical, // use true if content is not Json
optional headers as nullable record // optional HTTP headers as a record
) as any =>
let
query = query ?? [],
asRaw = asRaw ?? false, // toggles calling Json.Document() or not
headers = headers ?? [
Accept="application/json"
],
baseUrl = staticPath,
options = [
RelativePath = relativePath,
Headers = headers,
Query = query
// optionally toggle handling errors for specific HTTP Status codes
// ManualStatusHandling = {400, 404}
],
// wrap 'Response' in 'Binary.Buffer' if you are using it multiple times
response = Web.Contents(staticPath, options),
metadata = Value.Metadata(response),
buffered = Binary.Buffer(response),
result = Json.Document(buffered)
in
[
response = if asRaw then buffered else result,
status_code = metadata[Response.Status],
metadata = metadata
]
in
WebRequest
Chaining Web.Contents to Merge Many Queries
let
response_locations = WebRequest(
"https://www.metaweather.com",
"api/location/search",
[ lattlong = "36.96,-122.02" ]
),
location_schema = type table[
distance = number, title = text,
location_type = text, woeid = number, latt_long = text
],
cityListing = Table.FromRecords(response_locations[response], location_schema, MissingField.Error),
city_mergedRequest = Table.AddColumn(
cityListing,
"LocationWeather",
(row as record) as any =>
let
woeid = Text.From(row[woeid]),
response = WebRequest(
"https://www.metaweather.com",
"api/location/" & woeid,
[]
)
in
response,
type any
)
in
city_mergedRequest
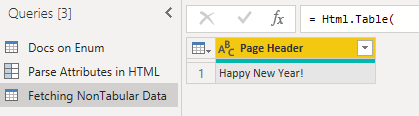
Html.Table – Parsing with CSS Selectors
Select a Single Element: an Image, url, text, etc…
This fetches the current heading text on the blog
let
Url = "https://powerbi.microsoft.com/en-us/blog/",
Response = Web.Contents( Url ),
/*
note: normally do not pass dynamic urls like this, see cheatsheet on preventing refresh errors
Non-tabular scraping like Images or any single elements, does not use a "RowSelector"
This CSS Selector finds exactly one element, the Page's Header Text
.section-featured-post .text-heading1 a
*/
HeaderText = Html.Table(
Response,
{
{ "Page Header", ".section-featured-post .text-heading1 a" }
}
)
in
HeaderText
Parsing Element’s Attributes
let
Url = "https://powerbi.microsoft.com/en-us/blog/",
Response = Web.Contents( Url ),
/*
The 3rd argument in "columnNameSelectorPairs" is the transformation function.
by default it uses:
each _[TextContent]
*/
HeaderAsElement = Html.Table(
Response,
{ { "Link", ".section-featured-post .text-heading1 a", each _ } }
),
ElementRecord = Table.ExpandRecordColumn(
HeaderAsElement, "Link",
{"TagName", "TextContent", "Attributes"}, {"TagName", "TextContent", "Attributes"}
),
ExpandedAttributes = Table.ExpandRecordColumn(
ElementRecord, "Attributes",
{"href", "rel", "title"}, {"attr.href", "attr.rel", "attr.title"}
)
in
ExpandedAttributes
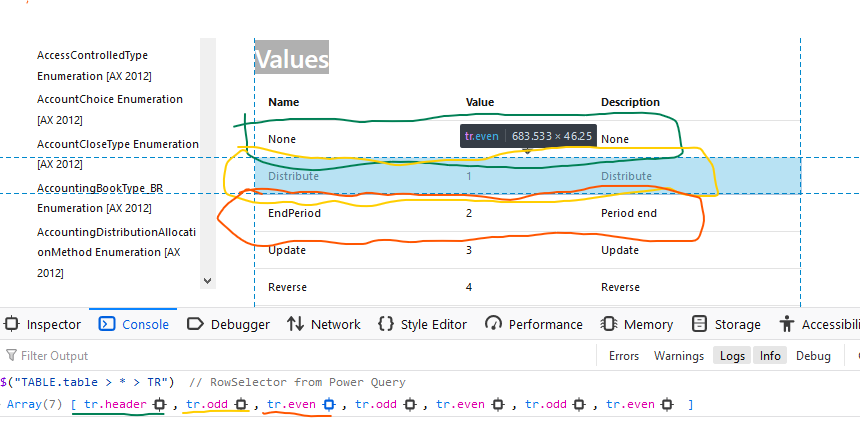
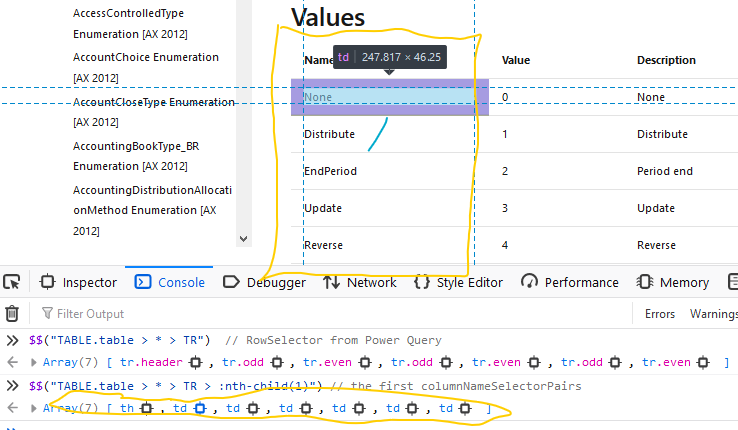
Select Tables using your own CSS Selectors
Results of the RowSelectorResults of columnNameSelectorPairs
// Docs on Enum
let
Source = "https://docs.microsoft.com/en-us/previous-versions/dynamics/ax-2012/reference/gg841505(v=ax.60)",
// note: normally do not pass dynamic urls like this, see cheatsheet on preventing refresh errors
Response = Web.BrowserContents( Source ),
/*
Think of "RowSelector" as selecting a table row
Then for every row, you select "columns" using the "columnNameSelectorPairs" selector
The combination gives you a table cell.
For more on CSS Selectors, see: <https://developer.mozilla.org/en-US/docs/Web/CSS/CSS_Selectors>
*/
columnNameSelectorPairs = {
// column names don't matter here, since I'm using .PromoteHeaders
{ "Column1", "TABLE.table > * > TR > :nth-child(1)" },
{ "Column2", "TABLE.table > * > TR > :nth-child(2)" },
{ "Column3", "TABLE.table > * > TR > :nth-child(3)" }
},
t1 = Html.Table(
Response, columnNameSelectorPairs,
[RowSelector = "TABLE.table > * > TR"]
),
t2 = Table.PromoteHeaders( t1, [PromoteAllScalars = true] ),
FinalTable = Table.TransformColumnTypes(
t2,
{ { "Name", type text }, { "Value", Int64.Type }, { "Description", type text} }
)
in
FinalTable
SQL Native Query
Parameterized SQL queries with Value.NativeQuery()
let
Source = Sql.Database("localhost", "Adventure Works DW"),
Test = Value.NativeQuery(
Source,
"SELECT * FROM DimDate
WHERE EnglishMonthName=@MonthName",
[
MonthName = "March",
DayName = "Tuesday"
]
)
in
Test
Other
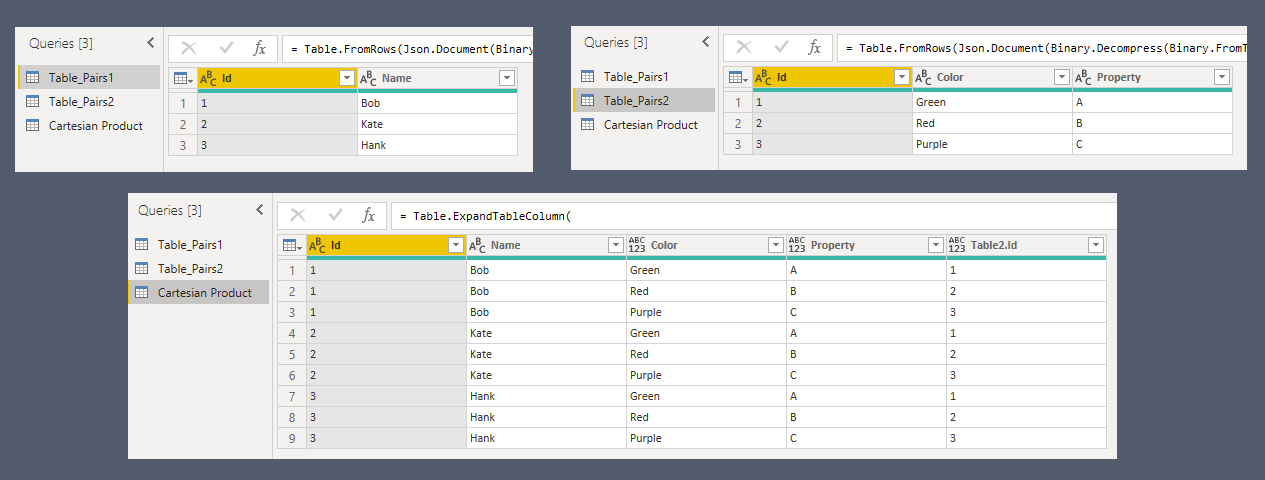
Cartesian Product
let
#"Add Column Pair2" = Table.AddColumn(
Table_Pairs1, "Pairs2",
each Table_Pairs2,
Table.Type
),
#"Expanded Pairs" = Table.ExpandTableColumn(
#"Add Column Pair2",
"Pairs2",
{"Color", "Property"},
{"Color", "Property"}
)
in
#"Expanded Pairs"
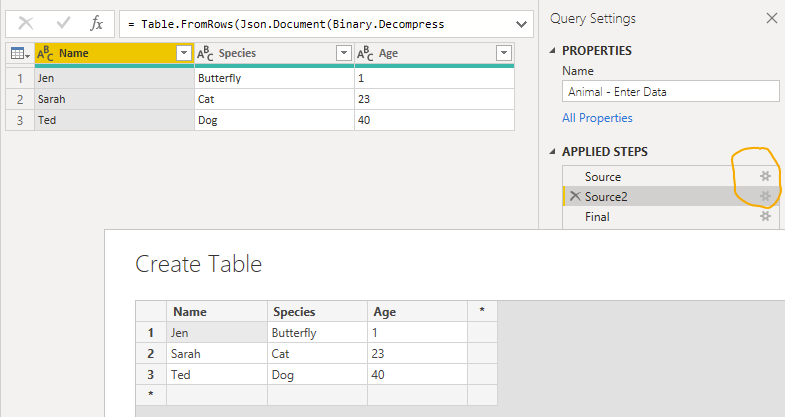
You can make start with ‘enter data’, then duplicate that line. You end up with two steps, each are their own enter data
let
Source = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("i45WcitKzEvOLFbSUfLJrEosSgEyTJRidaKVHHNSKxJTijITgSLuqcnZ+UDaEiwTkgpS5ZtfkgGkjJRiYwE=", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type nullable text) meta [Serialized.Text = true]) in type table [Name = _t, Species = _t, Age = _t]),
Source2 = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("i45W8krNU9JRciotKUktSsupBLINlWJ1opWCE4sSM4A858QSIGlkDBYMSU0Bclzy04GkiYFSbCwA", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type nullable text) meta [Serialized.Text = true]) in type table [Name = _t, Species = _t, Age = _t]),
Final = Table.Combine( { Source, Source2 } )
in
Final
Convert Table to JSON
TableToJson = (source as table, optional encoding as nullable number) as text =>
let
encoding = encoding ?? TextEncoding.Utf8,
bin = Json.FromValue(source, encoding),
jsonAsText = Text.FromBinary(bin, encoding)
in
jsonAsText
let
// Converts a list of any type to text. Works well on most types
// although to support all cases, it requires more logic
mixedList = {4, "cat", #date(1999,5,9), 0.4},
ListAsText = List.Transform(mixedList, each Text.From(_)),
CsvText = Text.Combine( ListAsText, ", ")
in
//output: "4, cat, 5/9/1999, 0.4"
CsvText
Functions
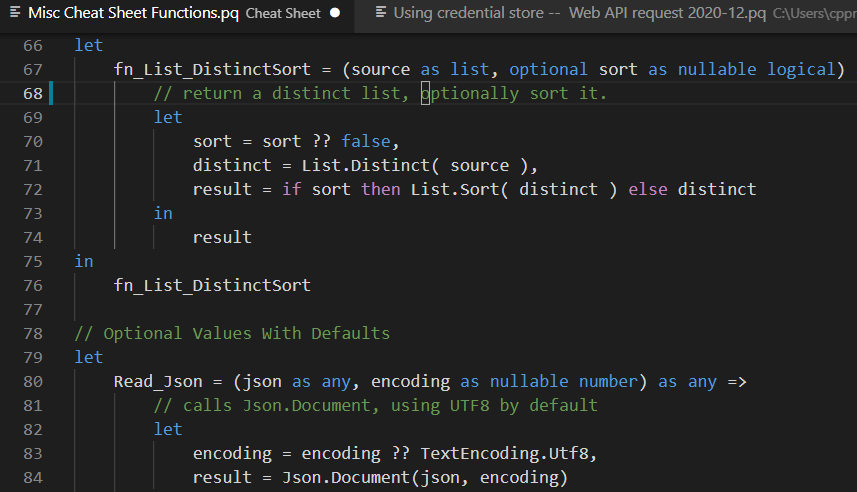
Using Optional Parameters with Default Values
The Null_coalescing_operator ?? simplifies default values. encoding will be set to what the user passed, unless it’s null. In that case, it is set to TextEncoding.Utf8
let
Read_Json = (json as any, encoding as nullable number) as any =>
// calls Json.Document, using UTF8 by default
let
encoding = encoding ?? TextEncoding.Utf8,
result = Json.Document(json, encoding)
in
result
in
Read_Json
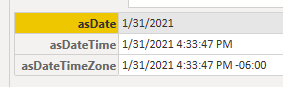
Mapping Function Calls based on Type
Caller chooses which type of conversioin to use, based on type names { date, datetime, datetimezone }
let
// 1] get a `type` from caller
// 2] return a difference function based on the type
GetTransformByType = (_type as type) as function =>
let
// originally from: <https://docs.microsoft.com/en-us/power-query/helperfunctions#tablechangetype>
func_transform =
if (Type.Is(_type, type date)) then Date.From
else if (Type.Is(_type, type datetime)) then DateTime.From
else if (Type.Is(_type, type datetimezone)) then DateTimeZone.From
else (t) => t // else return self
in
func_transform,
nowDtz = DateTimeZone.LocalNow(),
// invoke in 2 steps
toDate = GetTransformByType(type date),
callDate = toDate( DateTimeZone.FixedLocalNow() ),
// create, and invoke functions
Results = [
asDate = (GetTransformByType(type date))( nowDtz ),
asDateTime = (GetTransformByType(type datetime))( nowDtz ),
asDateTimeZone = (GetTransformByType(type datetimezone))( nowDtz )
]
in
Results
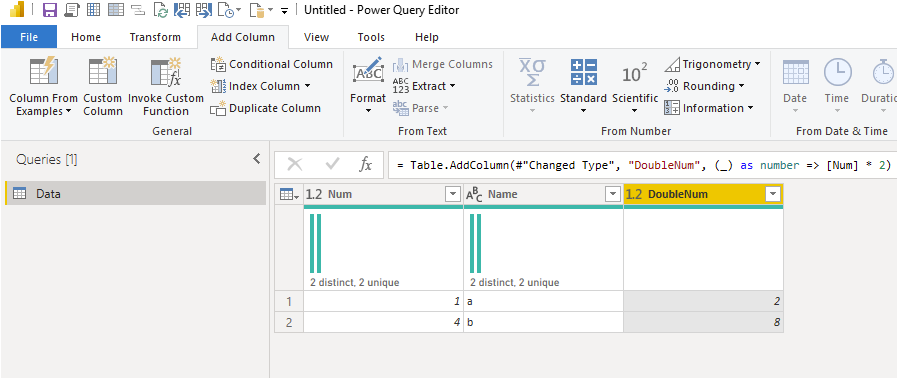
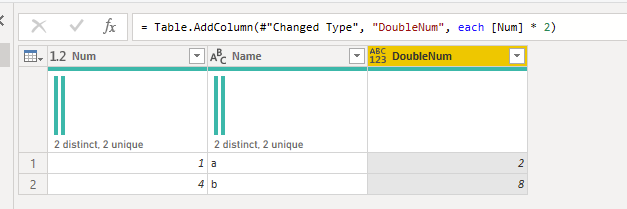
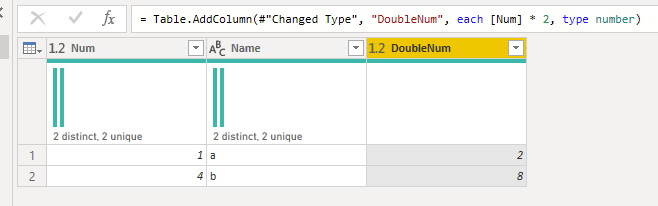
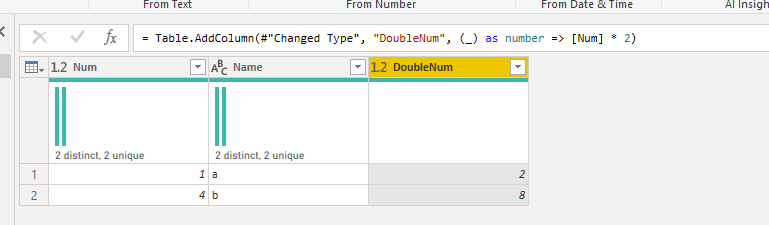
The default UI sets your column to type any.You can use the optional argument of Table.AddColumn to set it to numberOr you can declare your function’s return type
Why doesn’t the original [Num] * 2 work?
Powerquery does not know what type will be returned by your function. That’s because each is by definition a function that returns type any
The only function that Power BI is missing is Facebook.Graph (on my machine)
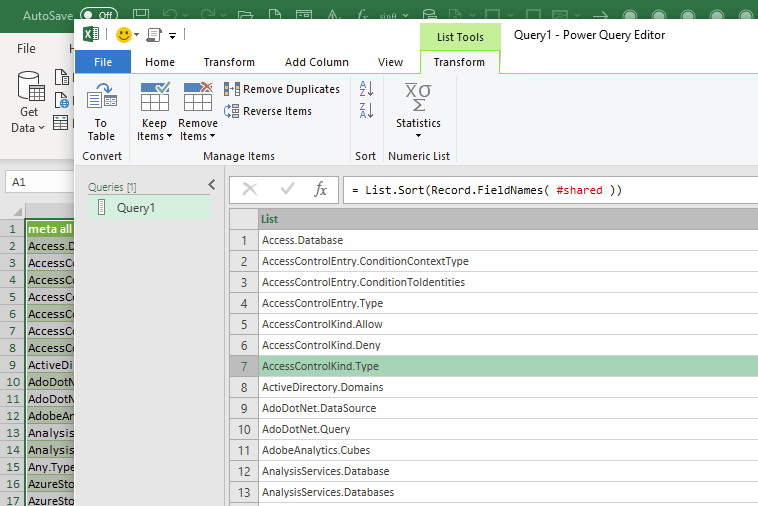
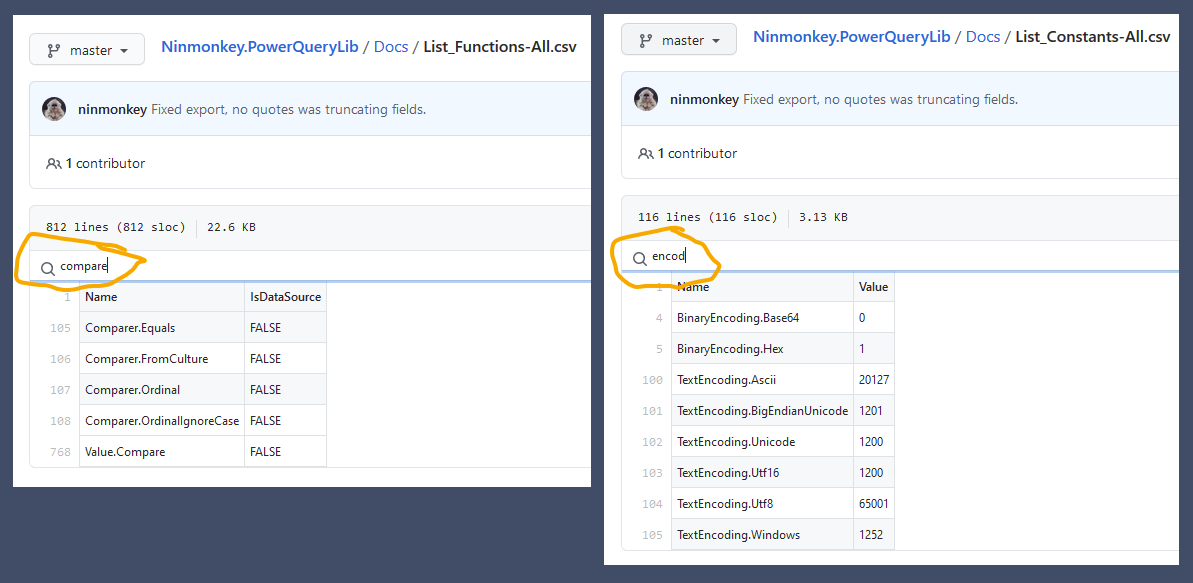
* This query checks for missing identifiers (which may be functions). ( You can filter by type if you convert #shared to a table instead of calling Record.FieldNames() )
Generating the list using #shared
To get a list of all identifiers (functions, variables, constants) I use the variable named #shared . Create a new blank query, then paste this
let
IdentifierList = List.Sort(Record.FieldNames( #shared ))
in
IdentifierList
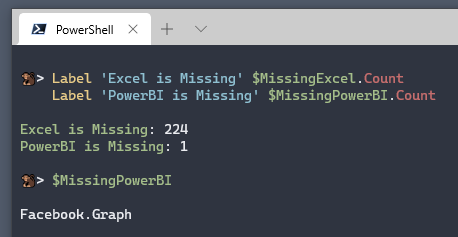
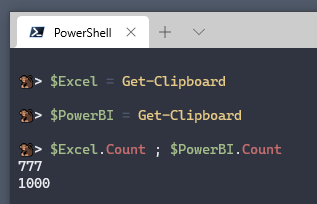
I copy using Copy Entire List, then storing the results into a PowerShell variable. I Repeat the same with Power BI.
That’s more than I expected.
To find out exactly which functions are different, use the Power Shell operator -NotIn
# Find functions in PBI but not Excel
$MissingExcel = $PowerBI | ? { $_ -notin $Excel }
# Find functions in Excel but not PBI
$MissingPowerBI = $Excel | ? { $_ -notin $PowerBI }
The list of functions Power BI is Missing
Facebook.Graph
The list of functions Excel is Missing
Note: This is the list for today, on my machine. Run the #shared query to find any changes.
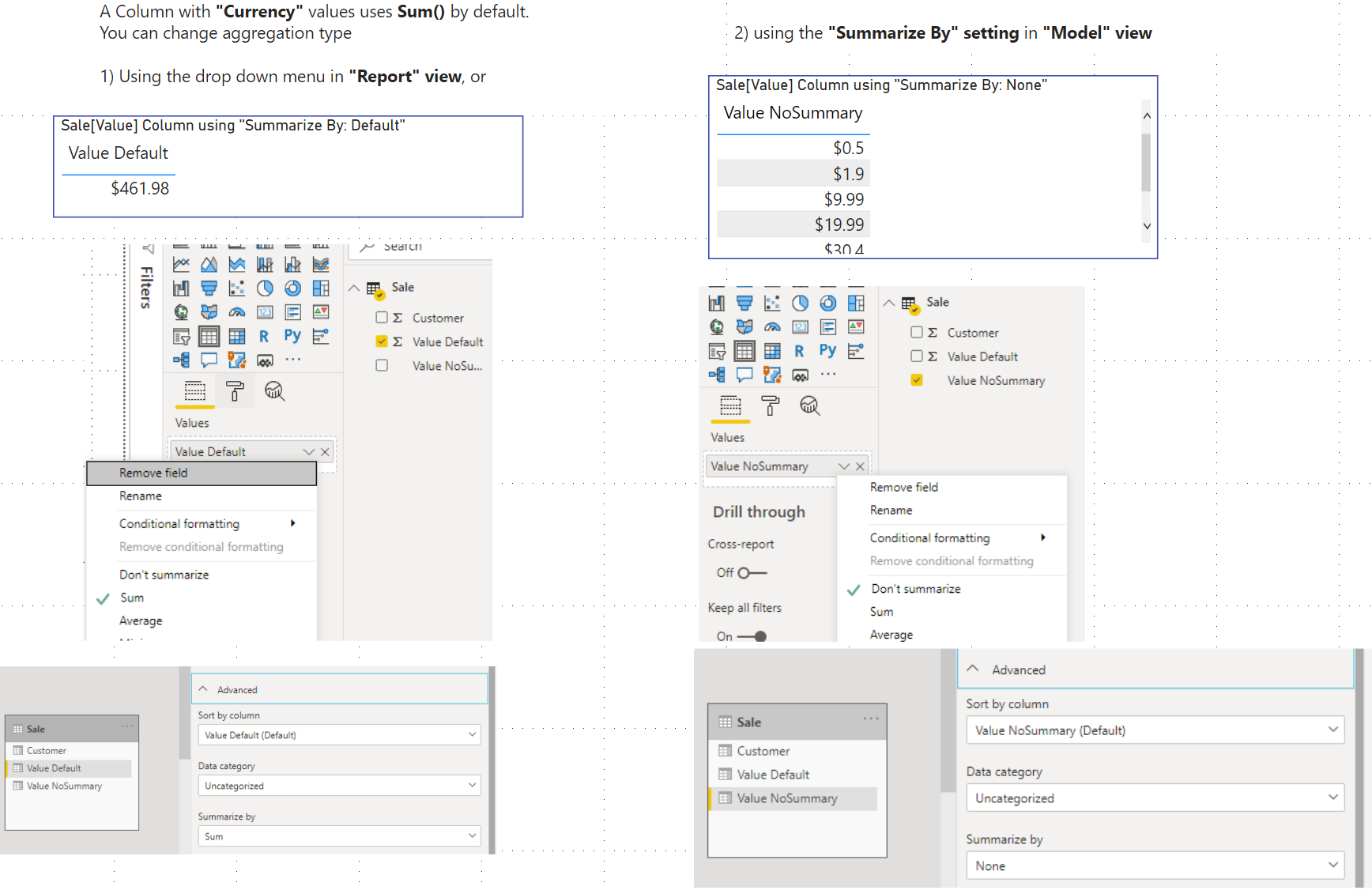
The Model view allows you to set a global default “Summarize By” type for every column. You still have the ability to override the aggregation type per-visual in Report view
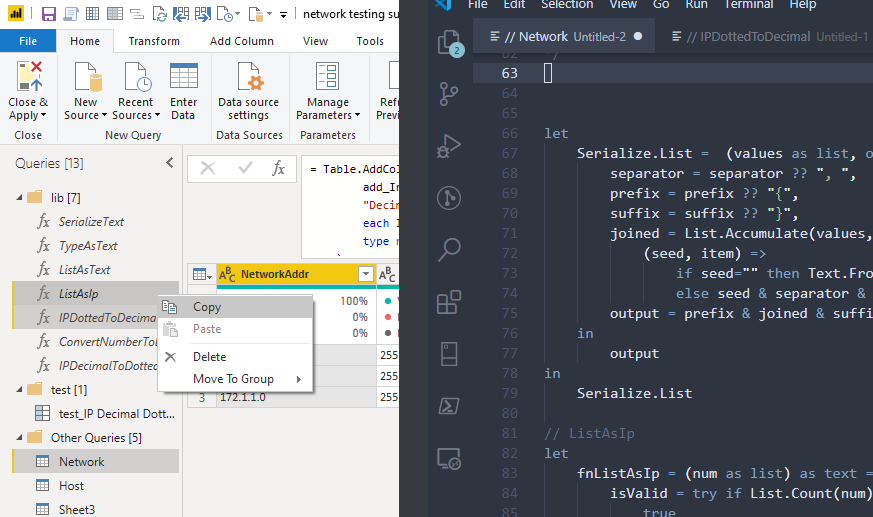
You can copy -> paste multiple queries into a new Power BI Report (notice it included a required referenced query ListAsText even though I didn’t select it.You can copy -> pastemultiple queries into at text editor
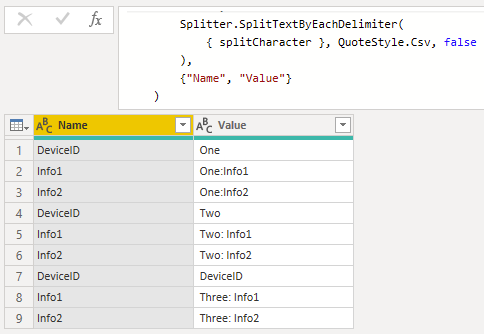
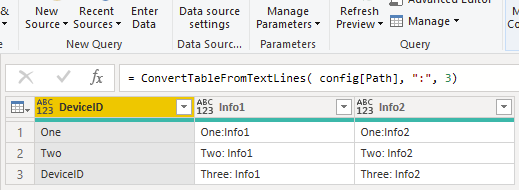
let ConvertTableFromText = (filepath as text, splitCharacter as text, linesPerRecord as number, optional encoding as nullable number) as table =>
let
TextLines = Lines.FromBinary(
File.Contents( filepath, null ),
null,
null,
encoding ?? TextEncoding.Utf8
),
TextLineTable = Table.FromColumns(
{ TextLines }, {"Line"}
),
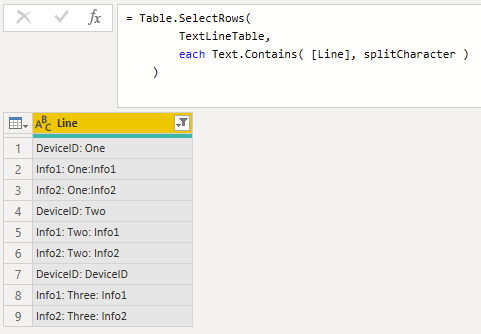
Pairs = Table.SelectRows(
TextLineTable,
each Text.Contains( [Line], splitCharacter )
),
SingleRecordAsCols = Table.SplitColumn(
Pairs,
"Line",
Splitter.SplitTextByEachDelimiter(
{ splitCharacter }, QuoteStyle.Csv, false
),
{"Name", "Value"}
),
TotalLines = Table.RowCount( SingleRecordAsCols ) ,
NumberOfGroups = TotalLines / linesPerRecord,
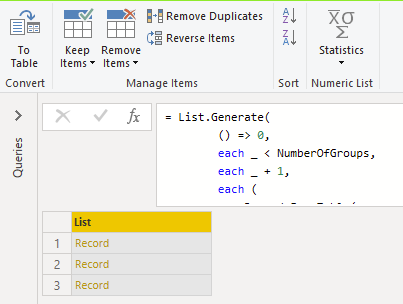
ListOfRecords = List.Generate(
() => 0,
each _ < NumberOfGroups,
each _ + 1,
each (
Record.FromTable(
Table.Range(
SingleRecordAsCols,
_ * linesPerRecord,
linesPerRecord
)
)
)
),
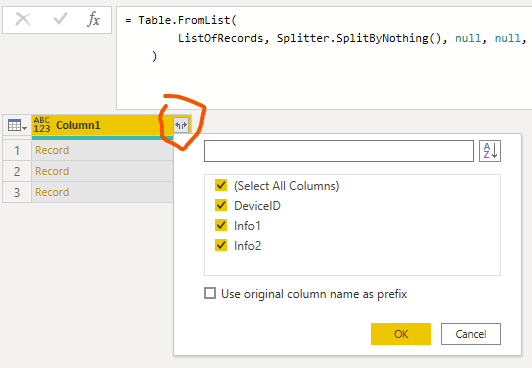
t = Table.FromList(
ListOfRecords, Splitter.SplitByNothing(), null, null, ExtraValues.Error
),
columnNameList = Record.FieldNames( ListOfRecords{0} ),
TableOfRecords = Table.ExpandRecordColumn(
t, "Column1", columnNameList, columnNameList
)
in
TableOfRecords
in
ConvertTableFromText
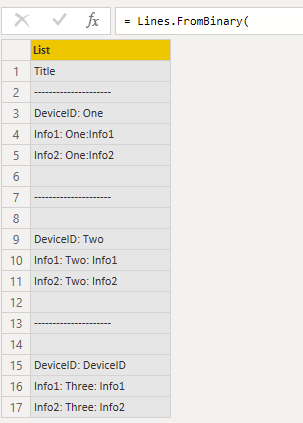
First we load the text file as a list. File.Contents( filepath ) reads all file types. Lines.FromBinary( Contents ) converts it into text. Depending on how the file was saved, you may need to set the encoding
Don’t worry if encoding sounds scary. If text loads with the wrong characters, try the other one. Two good ones to try first are:
TextEncoding.Windows
Power BI defaults to this for windows files
TextEncoding.Utf8
Anything on the internet uses UTF8 by default.
Tip: If a file truly is ASCII then UTF8 will work
Next remove any lines that are missing :
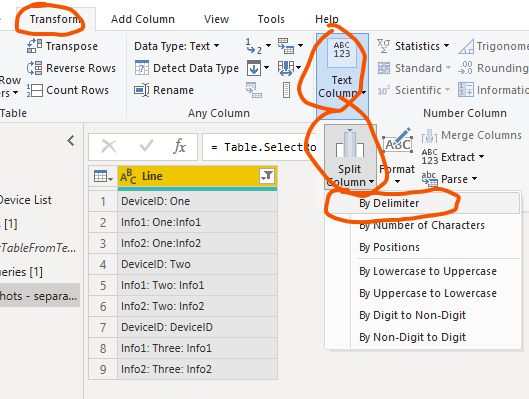
Then split each line into two columns: Transform Column -> Text -> Split -> By Delimiter
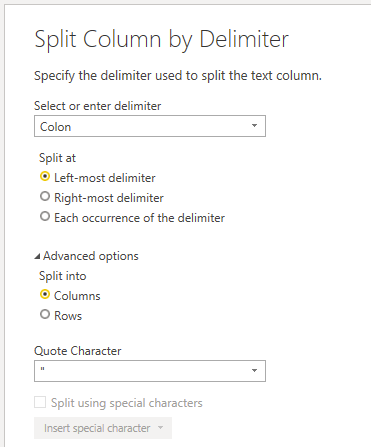
I started with these options
I renamed them to Name and Value because they will be converted into records.
To convert multiple lines into a single recordI used List.Generate. You can think of it like a for loop
There are
3 lines per record
9 total lines = the number of lines in the file
3 total groups = 9 total lines / 3 lines per record
We need to loop 3 times. I’ll recreate a loop like this, converted to Power Query